
How does Gen AI really work?
We are using ChatGPT, Claude, Gemini, DeepSeek, etc. We appreciated their ability to answer any queries we had. Do you ever think about how they understand our language? At the end of the day, it’s just a machine, right?
Are you really curious to know? Then bingo, you are in the right place…
“Transformer” is an architecture that set a benchmark in deep learning by overcoming various challenges, enabling the machine to understand language. To get a deeper understanding of this, we need to go beyond the history and examine how the machine actually tries to understand what we are conveying.
No more waiting, let’s get into it…
Section 1
The struggle: How machines tried to read
Imagine you’re teaching a child to read. But the thing is, the child has very short-term memory. By the time they reach the end of the sentence, they have forgotten the beginning. That was exactly the problem with the early AI models.
How did machines read before?
In the 1980s, scientists wanted to teach machines to understand the language – things like translation, summarisation, and answering questions. So, they came up with something called Recurrent Neural Networks (RNNs).
How RNNs work – The simple idea
Think of RNN like a person reading a book with a sticky note.
- They read one word at a time
- After each word, they update their sticky note with a summary of what they’ve read so far
- They carry that sticky note to the next word
So, for the sentence: “The cat sat on the mat”
The RNN reads: “The” → updates note → “cat” → updates note → “sat” → updates note… and so on.
The problem: The sticky note gets full!
The sticky note has limited space. For short sentences, it works fine!
But for long sentences like:
“The trophy that John bought last summer from the shop near his hometown didn’t fit in the bag because it was too big.”
By the time the RNN reaches “it”, the sticky note is so full and overwritten that it has almost forgotten “trophy” from the beginning!
This is called the Vanishing Gradient Problem – the memory of early words vanishes as the sentence grows longer.
Scientists tried to fix it: LSTM!
In 1977, scientists decided to give the sticky notes a better system, one that decides what to remember and what to forget. Then the LSTM (Long Short-Term Memory) was introduced.
Think of LSTM like a sticky note with three smart filters:
- Forget Gate: “Should I erase this old info?”
- Input Gate: “Should I add this new info?”
- Output Gate: “What should I share with the next word?”
LSTMs were much better than plain RNNs! But they still had big problems:
The remaining problems even after LSTM
Problem 1: Still slow
RNNs and LSTMs must read word by word, one after another. You can’t skip ahead. This means:
- Training on huge datasets takes more time
- You can’t use the full power of modern GPUs (which are capable of doing many things at the same time)
Problem 2: Still forgets long distances
Even LSTMs struggled when the related words were very far apart in a long paragraph.
Problem 3: Hard to Scale
The bigger you made the model, the harder and slower it became to train. So the scaling is not good.
The Breaking Point: 2017
By 2014-2016, Google were building translation systems, and even the best RNN/LSTM models kept making mistakes on long sentences.
Then they thought:
“Why can’t the model just look at the whole sentence at once and figure out which words are related, like a human does?”
And that question… changed everything.
The Key Insight
A human reading “The trophy didn’t fit because it was too big” doesn’t read it word by word and forget. They:
- Read the whole sentence at once
- Instantly connect “it” to “trophy” because of context
- Understand the relationship between distant words effortlessly
What if a machine could do the same? What if, instead of a sticky note passed word by word, the model could pay attention to every word simultaneously?
That idea became the Attention Mechanism, and it became the heart of the Transformer. So, some Google researchers published a paper titled “Attention Is All You Need” in 2017.
Section 1: summary
| Era | Model | Problem |
|---|---|---|
| 1980s–90s | RNN | Short memory, slow, forgets early words |
| 1997 | LSTM | Better memory, but still slow & hard to scale |
| 2014–16 | Better LSTMs | Still struggles with very long sequences |
| 2017 | Transformer | Reads everything at once: The revolution |
Section 2
The breakthrough: The magic of attention
Imagine someone asks you: “Hey, what did Sarah say about the weather earlier?”
Your brain doesn’t process word by word. Instead, it instantly focuses on:
- Sarah
- The weather topic
- That specific moment in the evening
You filtered out everything irrelevant and zoomed in on what mattered. That’s exactly what Attention does in Transformer!
What is attention – simply put
Attention is the ability of the model to find the relation between the words in a sentence/paragraph.
Let’s take an example:
“The trophy didn’t fit in the bag because it was too big.”
When the model processes the word “it”, Attention helps it look at all other words and gives each one a relevance score:
| Word | relevance score for “it” |
|---|---|
| The | 2% |
| trophy | 85% <- High! |
| didn’t | 1% |
| fit | 5% |
| bag | 6% |
| because | 1% |
So, the model learns, “it” most likely refers to “trophy”
This scoring process is called Self-Attention, every word attends to every other word in the same sentence.
The secret ingredients: Q, K, V
Now here’s where it gets slightly technical.
Think of a YouTube search:
- Query (Q) = What you type in the search bar (“funny cat videos”)
- Key (K) = The titles/tags of all videos on YouTube
- Value (V) = The actual video content
When you search, YouTube matches your Query against all Keys, finds the most relevant ones, and returns those Values to you.
Attention works the same way:
- Q (Query) → “What am I looking for?” The current word asking the question
- K (Key) → “What do I contain?” Every other word advertising itself
- V (Value) → “What do I actually give?” The actual information passed forward
Multi-Head attention: watching from many angles
What if, instead of doing attention once, you did it multiple times in parallel, each focusing on a different aspect?
Think of it like watching a movie with multiple critics simultaneously:
- Critic 1 focuses on grammar relationships (“trophy” is the subject)
- Critic 2 focuses on meaning/semantics (“it” = “trophy”)
- Critic 3 focuses on positional relationships (how far apart words are)
Each critic watches independently and gives their own take. Then you combine all their opinions for a richer understanding.
That’s Multi-Head Attention, running attention multiple times in parallel, each head learning different relationships!
Why this was revolutionary
| RNN (Old) | Attention (New) | |
|---|---|---|
| How it reads | Word by word | All words at once |
| Long-distance relationships | Often misses them | Handles perfectly |
| Speed | Sequential, slow | Parallel, fast |
| “it” → “trophy” problem | Struggles | Solves easily |
Section 2: summary
3 Key Ideas
- Self-Attention → Every word looks at every other word and scores relevance
- Q, K, V → Like a search engine, Query matches Keys to retrieve Values
- Multi-Head attention → Run attention multiple times in parallel, each catching different patterns
The genius of Attention is that it’s not hardcoded, the model learns by itself which words to pay attention to, just by training on data. Nobody told it “trophy = it”. It figured it out on its own!
“Instead of building memory step by step like RNNs, just let every word talk to every other word directly. Let them figure out who’s important.” – The core philosophy of Attention
Section 3
The architecture: How it all fits together
So far, we know:
- Section 1: RNNs failed because they read word by word and forgot
- Section 2: Attention, let every word talk to every other word directly
Now the researchers had a powerful tool – Attention. But a single tool doesn’t make a full model. They needed to build a complete machine around it. That machine is the Transformer.
The big picture: A factory analogy
Think of the Transformer like a translation factory with two departments:
“Je suis étudiant” → [FACTORY] → “I am a student”
- Encoder department – Reads and deeply understands the input
- Decoder department – Uses that understanding to generate the output
Let’s walk inside each department!
The encoder – The understanding department
The Encoder reads the input sentence and builds a rich understanding of every word in context.
It has 6 identical floors (layers), and each floor does the same 4 steps:
Step 0 – Input embedding + Positional encoding
Before entering the encoder, each word is converted into a vector (a set of numbers). But since Transformers read everything at once, we also add positional encoding, a way of telling the model “this word is 1st, this is 2nd…”
Think of it like numbering seats in a cinema before everyone sits down
Step 1 – Multi-Head self attention
Every word looks at every other word and figures out relationships – exactly what we learned in Section 2!
“trophy” and “it” are related → pay attention to each other
Step 2 – Feed Forward Network (FFN)
After attention, each word passes through a small neural network independently. This adds more processing power.
It helps the model gain a better understanding of the respective word. Through this process, model will get to know that this word is related to
- movement
- speed
- physical action
- past event
Step 3 – Add & normalise
After each step, the result is added back to the original input and normalised (kept stable). This helps the model not forget what it started with. Like always, keep a copy of the original document while editing
After traversing all 6 floors, the encoder produces a deep, context-rich representation of the entire input sentence. (Here, 6 is just a sweet spot; modern models might have more layers for even deeper understanding.)
The Decoder: The generation department
The Decoder takes the encoder’s understanding and generates the output word by word.
It also has 6 floors:
Step 1: Masked self-attention
The decoder looks at the words it has already generated – but they’re masked, so it can’t cheat by looking at future words it hasn’t generated yet!
Here, the word ‘cheat’ means that if the model knows the entire sentence during this step, it will just copy the translation for the next word and doesn’t learn anything about it.
Let’s take the sentence “I am a student.” How should it be translated into French?
The model should learn about this sentence, not just copy-paste the translation from its training data. So while it’s processing “I”, the other two words (“am”, “student”) are masked, and then it learns about “am” as a verb. Otherwise, it’ll be like “I know the next word, so I just copied the answer”, then it never learn.
Step 2: Cross attention
This is the magic bridge! The decoder looks at the encoder’s output and asks:
“Which parts of the input should I focus on to generate my next word?”
This is how the model connects input and output, like a translator constantly glancing back at the original text while writing the translation.
Step 3: Feed Forward Network
Same as encoder, extra processing power for each position. Finally, the decoder outputs a probability distribution over all words in the vocabulary and picks the most likely next word!
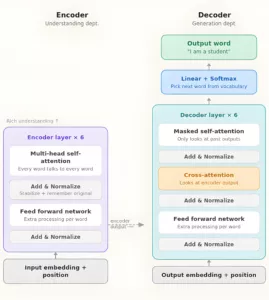
The key bridge – Cross attention
The most important connection in the whole architecture is that dashed arrow between Encoder and Decoder – Cross Attention.
This is how the decoder says:
“I’m about to generate the word ‘student’ – let me look back at the French input and focus on the word ‘étudiant'”
Without this bridge, the decoder would have no idea what it’s translating!
Do all models use both Encoder and Decoder?
| Model | Uses | Good for |
|---|---|---|
| BERT | Encoder only | Understanding text — search, classification |
| GPT / Claude | Decoder only | Generating text — writing, chatting |
| Original Transformer | Both | Translation, summarisation |
Section 3: summary
The Transformer has two departments:
Encoder → Reads input → applies self-attention → feed forward → repeats 6 times → outputs deep understanding
Decoder → Takes encoder output → masked self-attention (no peeking!) → cross-attention (bridges to encoder) → feed forward → picks next word → repeats until done
Section 4
The magic numbers: math behind the transformer
Don’t be scared, I know “math behind AI” is always scary.
The Transformer uses just 4 math operations. That’s it. Addition, Multiplication, Division, and a special function called Softmax. You already know 3 of them from school!
Let’s build up from scratch.
The building blocks – What are we calculating?
The entire Transformer is doing one thing repeatedly: “Given these words, what’s the best next word?”
To answer that, it needs to do math on words. But it’s not possible to do math on words directly – so first we convert words to numbers.
Step 0 – Words become numbers (Embeddings)
Every word gets converted into a list of numbers called a vector.
Notice something beautiful – similar words have similar numbers!
“cat” → [0.2, 0.8, -0.3, 0.5]
“dog” → [0.3, 0.7, -0.2, 0.4]
“trophy” → [0.9, -0.1, 0.6, 0.2]
“banana” → [-0.4, 0.3, 0.1, -0.8]
“cat” and “dog” are both animals → their vectors are close to each other.
“banana” is very different → its vector looks nothing like “cat” or “dog”.
This is called a vector space — words live in a mathematical space where distance = meaning similarity.
Step 1 – Add position (Positional Encoding)
Since the Transformer reads all words at once, it needs to know word order. So, we add a position signal to each word’s vector:
“cat” at position 1 → [0.2, 0.8, -0.3, 0.5] + [0.0, 1.0, 0.0, 1.0] = [0.2, 1.8, -0.3, 1.5]
“cat” at position 5 → [0.2, 0.8, -0.3, 0.5] + [0.9, 0.6, 0.1, 0.5] = [1.1, 1.4, -0.2, 1.0]
Same word, different position → different final vector!
The position signal uses a clever pattern of sine and cosine waves – like a unique fingerprint for each position.
Step 2 – The Attention math (The heart!)
We already have a sense of it in Section 2.
Let’s now see the actual numbers flowing through.
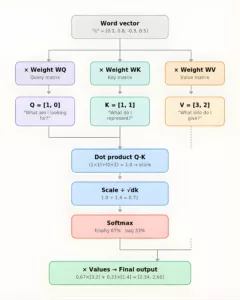
Creating Q, K, V
Each word’s vector gets multiplied by 3 learned weight matrices to produce Q, K, V:
Word vector × Weight matrix WQ = Query (Q)
Word vector × Weight matrix WK = Key (K)
Word vector × Weight matrix WV = Value (V)
The Full Calculation – With Real Numbers!
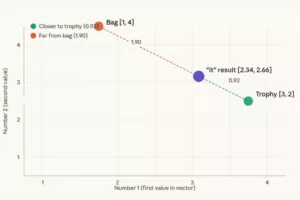
Let’s use tiny vectors to keep it simple. Say we have 2 words:
Q for “it” = [1, 0]
K for “trophy” = [1, 1]
K for “bag” = [0, 1]
V for “trophy” = [3, 2]
V for “bag” = [1, 4]
Step A – Dot products (relevance scores)
“it” vs “trophy”: (1×1) + (0×1) = 1
“it” vs “bag”: (1×0) + (0×1) = 0
Step B – Scale by √dk (dk = 2, so √2 ≈ 1.4): (dk is the size of the vector; here, we took simple vectors like [1, 0], so dk = 2)
1 ÷ 1.4 = 0.71
0 ÷ 1.4 = 0.00
Step C – Softmax
trophy: e^0.71 ÷ (e^0.71 + e^0.00) = 2.03 ÷ 3.03 = 0.67 → 67%
bag: e^0.00 ÷ (e^0.71 + e^0.00) = 1.00 ÷ 3.03 = 0.33 → 33%
Step D – Weighted sum of Values
Final = 0.67 × [3,2] + 0.33 × [1,4]
= [2.01, 1.34] + [0.33, 1.32]
= [2.34, 2.66]
This [2.34, 2.66] is the new, context-aware representation of “it” — heavily influenced by “trophy”!
Let’s visualise the full math flow!
Step 3 – Feed Forward Network
After attention, each word passes through a simple neural network independently:
Input vector → Multiply by weights → Add bias → ReLU → Multiply again → Output
What is ReLU?
The simplest function in deep learning:
ReLU(x) = x if x > 0
ReLU(x) = 0 if x < 0
This adds extra learning capacity – the model can capture patterns that attention alone might miss.
Step 4 – Add & normalise
After every major step, two things happen:
Add (Residual Connection):
Output = Layer_output + Original_input
The original input is added back so the model never completely forgets where it started. Like keeping your rough draft while writing the final version
Normalise: All numbers are rescaled to have a mean of 0 and variance of 1 – keeping everything stable and preventing numbers from exploding or vanishing during training.
The Full math – all together
Here’s every operation in the Transformer, in order:
| Step | Operation | What it does |
|---|---|---|
| 0 | Word → Vector | Convert words to numbers |
| 1 | + Position encoding | Add word order info |
| 2 | × WQ, WK, WV | Create Q, K, V views |
| 3 | Q·KT ÷ √dk | Score relevance |
| 4 | Softmax | Convert to percentages |
| 5 | × V | Collect weighted info |
| 6 | Feed forward + ReLU | Extra processing |
| 7 | Add + Normalize | Stabilise and remember |
| 8 | Repeat × 6 | Go deeper into each layer |
| 9 | Final linear + Softmax | Pick the output word |
All of modern AI — GPT, Claude, Gemini – is just these simple operations repeated millions of times on billions of words. No magic. Just:
Multiply. Add. Normalise. Repeat.
The intelligence doesn’t come from complex math – it comes from doing simple math at an enormous scale.
Section 5
Changing the world: Real applications
We know the entire Transformer from scratch:
- Section 1 – RNNs failed, needed something better
- Section 2 – The attention mechanism was the breakthrough
- Section 3 – Encoder + Decoder architecture
- Section 4 – The math that makes it all work
Now let’s see what happened when this architecture was unleashed on the world!
The wave of applications
The Transformer didn’t just improve one thing. It revolutionised everything it touched. Let’s go application by application.
1. Conversational AI – Chatbots & Assistants
The most visible impact. This is where GPT, Claude, and Gemini live.
These are all decoder-only Transformers – they keep predicting the next word, one at a time, until they form a complete response.
When you type “Explain quantum physics simply” – the model:
- Converts your words into vectors
- Runs attention across all your words
- Predicts the most likely next word
- Keeps going word by word until done
Simple idea, enormous scale!
2. Search engines – Google & beyond
Before Transformers, Google matched your query to pages using keywords.
Search: “good place to eat near me, Italian” → finds pages containing those exact words.
After Transformers, Google uses BERT (Bidirectional Encoder Representations from Transformers) to understand meaning:
Search: “I’m hungry and want pasta” → understands you want Italian food nearby!
Google called BERT “the biggest leap forward in search in the past five years” when they launched it in 2019. It now powers billions of searches every day.
3. Language translation – Breaking barriers
This was the original use case of the Transformer paper! Google Translate, DeepL – all powered by Transformers.
Before 2017, translations were clunky and often wrong. After 2017, translations became remarkably natural.
The encoder reads the source language deeply → the decoder generates the target language word by word → cross attention bridges the two languages.
“Je suis étudiant” → “I am a student”
Today, Transformers translate between 100+ language pairs in real time – breaking down communication barriers across the world.
4. Image generation – DALL-E, stable diffusion, midjourney
Are you wondering how this language model works with images?
Here’s the mind-blowing part. Researchers discovered:
Images can be treated like sentences – break them into small patches instead of words!
Each image patch becomes a “word” vector. Attention figures out how patches relate to each other. The result? The model understands images as deeply as it understands language!
When you type “a cat riding a bicycle on the moon” – the Transformer:
- Understands your text description deeply (encoder)
- Generates image patches one by one (decoder)
- Uses cross attention to make sure the image matches the text
Pure Transformer magic!
5. Science & medicine – AlphaFold
This is perhaps the most important real-world application – one that could save millions of lives.
The problem: Proteins are the building blocks of life. Their shape determines their function. But figuring out a protein’s 3D shape from its chemical sequence took scientists years of lab work.
The solution: DeepMind built AlphaFold – a Transformer that treats protein sequences like sentences and predicts their 3D structure in minutes.
AlphaFold has already predicted the structure of 200 million proteins – essentially every known protein on Earth. This is accelerating drug discovery for cancer, Alzheimer’s, and countless other diseases. The scientists behind it won the Nobel Prize in Chemistry in 2024.
6. Code generation – GitHub Copilot
Every software developer’s assistant!
GitHub Copilot is a Transformer trained on billions of lines of code. It understands code the same way language models understand text – as sequences with patterns and meaning.
You type a comment:
# function to find all prime numbers up to n
Copilot writes the entire function for you! It attends to your comment, your existing code, and patterns from millions of similar programs to generate exactly what you need.
The full landscape
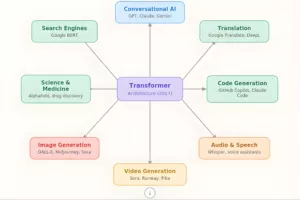
The common thread
Notice something – every single application uses the same core idea:
Break the input into pieces → convert to vectors → run attention → generate output
Whether the pieces are words, image patches, protein sequences, or code tokens, the architecture is the same!
That’s why the Transformer is so powerful. It’s a general-purpose intelligence machine – not built for one specific task, but adaptable to almost anything.
Section 5: summary
One architecture – six revolutions:
- Chatbots – natural conversation with AI
- Search – understanding meaning, not just keywords
- Translation – breaking language barriers
- Images – generating art from text
- Science – solving protein structures, accelerating medicine
- Code – writing software automatically
Conclusion
The whole idea is to make the machine understand the meaning of language so it can predict the next word, just as the human brain does.
The earlier architectures (RNN, LSTM) had many challenges, so the models built on them were not even capable of handling translation for longer paragraphs. It was also a nightmare to create and scale up big models using these architectures.
This pushed some Google researchers to think differently – “Why can’t the machine just read and think like a human?” Then they came up with a solution called Transformers. And now we are experiencing its revolution.
The Transformer architecture helps create powerful models capable of handling almost any task. It has components like:
- Attention (simple math which executes repeatedly)
- Encoder (reads and understands the input deeply)
- Decoder (generates the output word by word)
The interesting part is that it processes the entire sentence at once, so training the model is much faster and easier than with previous architectures. So, all the models which we use today are either fully or partially based on this architecture, depending on their use case.
What problem did early language models have?
Early models such as RNNs processed text one word at a time and struggled to remember information from earlier in long sentences. This made them slow, harder to scale, and less reliable when handling long-range context.
How did LSTMs improve on RNNs?
LSTMs added a more structured memory system, using mechanisms that decide what to remember, what to forget, and what to pass forward. They improved performance, but they still processed text sequentially and remained limited for very long inputs.
Why was the Transformer architecture such a breakthrough?
The Transformer changed the approach by allowing a model to look at all words in a sentence at once instead of reading them one by one. This made it much better at understanding relationships between distant words and much faster to train at scale.
What does “attention” mean in a Transformer?
Attention is the mechanism that helps the model determine which words are most relevant to each other in a sentence. When the model processes one word, it can look across the full sentence and assign importance to the other words based on context.
What is self-attention?
Self-attention means that each word in a sentence can compare itself with every other word in the same sentence. This helps the model work out meaning, references, and relationships without relying on a step-by-step memory chain.
What are Q, K, and V in simple terms?
Q, K, and V stand for Query, Key, and Value. They are three learned representations used in attention. The Query asks what the current word is looking for, the Keys describe what other words contain, and the Values carry the information that gets passed forward.
What is multi-head attention?
Multi-head attention means the model runs the attention process several times in parallel, with each head learning to focus on different kinds of relationships. One head may focus more on grammar, another on meaning, and another on position or structure.
Why do Transformers need positional encoding?
Because Transformers process all words at once, they need an additional way to understand word order. Positional encoding adds information about each word’s place in the sequence so the model can distinguish between different arrangements of the same words.
What is the difference between an encoder and a decoder?
The encoder is designed to read and build a deep understanding of the input, while the decoder generates output one step at a time. In the original Transformer, both work together, but some modern models use only one side depending on the task.
Why are GPT-style models called decoder-only models?
GPT-style models are called decoder-only because they focus on generating text by predicting the next token repeatedly. They do not use the full encoder-decoder structure of the original Transformer, but they still rely on the same core attention principles.
Is the maths behind Transformers very complicated?
The core operations are simpler than many people expect. At a high level, the model repeatedly performs multiplication, addition, scaling, normalisation, and softmax-based weighting. The power comes less from exotic maths and more from repeating these operations at very large scale.
What are some important real-world uses of Transformers?
Transformers now underpin many major AI applications, including chatbots, search, translation, code generation, image generation, and scientific tools such as protein-structure prediction. The same core architecture has proved adaptable across many different kinds of data and tasks.